Kenalan dengan Language Model
- Get link
- X
- Other Apps
Kenalan dengan Language Model
Pernahkah Anda merasa bahwa komputer atau ponsel bisa “membaca pikiran”? Misalnya saat Anda baru mengetik “Aku lagi lapar, pengen…” dan layar tiba-tiba menyarankan “makan bakso”. Rasanya seperti adamakhluk tak kasat mata yang memahami keinginan kita bahkan sebelum selesai menuliskannya. Sebenarnya, itu bukan sulap. Itu adalah hasil kerja dari sebuah teknologi canggih bernama model bahasa —sebuah sistem pintar yang dirancang untuk memahami dan memprediksi bahasa manusia.
Dalam dunia AI, model bahasa adalah salah satu jenis model mesin pembelajaran yang bertugas untuk memprediksi kata berikutnya dalam sebuah kalimat. Ia bekerja seperti pemain menebak-tebakan kata yang sangat terlatih.
Jika seseorang berkata, “Kalau hujan turun di atap rumahku, aku biasanya…”, model ini akan mencoba menyelesaikannya dengan berbagai kemungkinan: tidur, masak mi, mendengarkan musik, dan seterusnya.
Model bahasa tidak hanya menebak secara sembarangan. Ia menimbang dan menghitung kata atau frase berikutnya dalam sebuah kalimat untuk menentukan pilihan yang paling masuk akal.
Model bahasa menghitung probabilitas berbagai kata berdasarkan pelatihan dari jutaan bahkan miliaran contoh kalimat yang pernah dipelajari sebelumnya.
“Kalau hujan turun di atap rumahku, aku biasanya…” “…tidur.” (9.4%) |
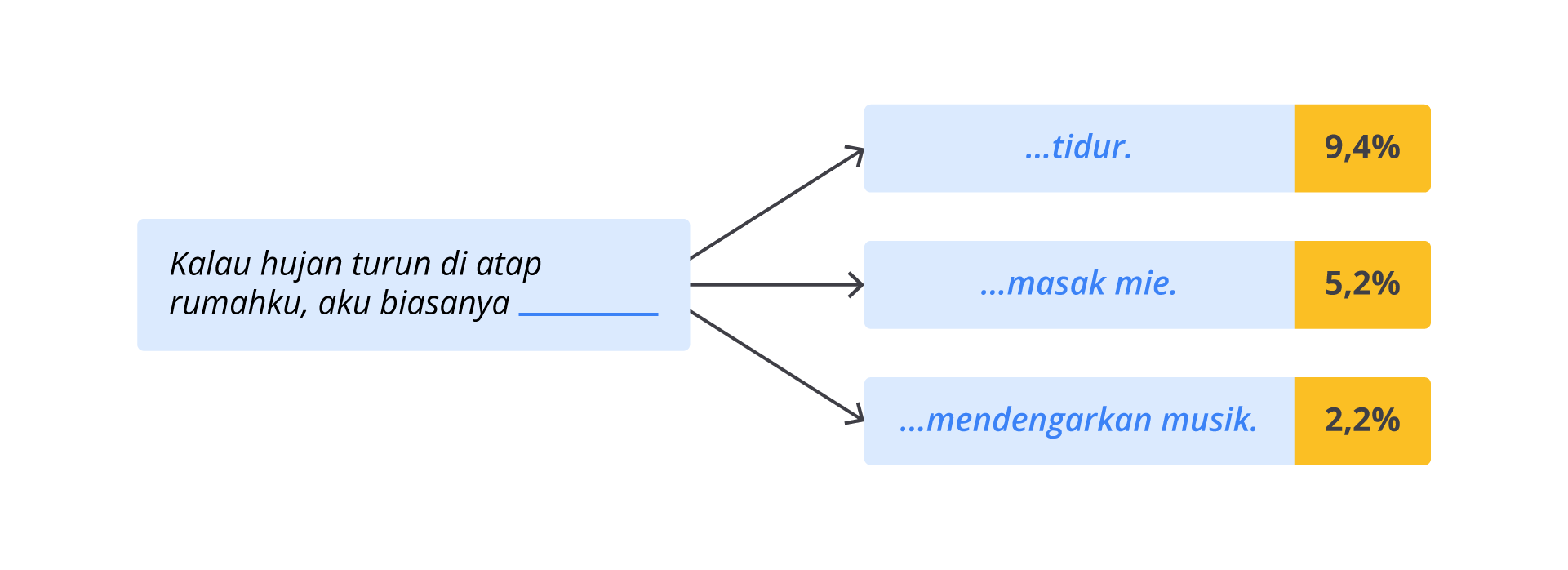
Model akan memilih berdasarkan probabilitas tertinggi atau secara acak dari kandidat yang paling masuk akal. Semakin sering kombinasi kata tertentu muncul di dunia nyata (dalam data pelatihan), semakin tinggi kemungkinan model memilihnya.
Memperkirakan kemungkinan dari daftar yang akan datang selanjutnya dalam suatu urutan yang berguna untuk berbagai hal, yaitu membuat tulisan, menerjemahkan bahasa, menjawab pertanyaan, dan masih banyak lagi. Semuanya dimulai dari mengisyaratkan kata.
Model ini tidak hanya digunakan pada fitur autocomplete , tetapi juga dalam aplikasi terjemahan, chatbot , asisten virtual, dan masih banyak lagi.
Model ini semakin lama semakin canggih. Tidak cukup hanya menebak satu kata, para peneliti mulai membangun model yang bisa memahami dan menghasilkan satu paragraf, bahkan seluruh artikel. Model yang semakin besar ini dibor dengan miliaran kalimat, menggunakan ribuan komputer yang bekerja tanpa henti. Jadi, lahirlah generasi baru yang kita sebut model bahasa besar .
LLM: Model Bahasa Versi Canggih
Seiring waktu, para ilmuwan dan insinyur komputer menyadari bahwa semakin besar model—semakin banyak data yang mereka pelajari serta semakin rumit struktur mereka—semakin pintar pula hasilnya.
Inilah yang disebut model bahasa besar atau LLM: versi super dari model bahasa yang dibor dengan jumlah data masif dan kapasitas pengiriman luar biasa . LLM adalah otak digital raksasa yang dapat berkomunikasi, menjawab pertanyaan, menulis cerita, merangkum artikel, bahkan menulis kode pemrograman.
Pembuatan model bahasa dalam skala besar adalah usaha yang sangat kompleks dan memerlukan banyak sumber daya. Riset untuk membuat model bahasa dan model bahasa besar saat ini telah berlangsung selama beberapa dekade.
Model bahasa awalnya hanya dapat memprediksi probabilitas dari satu kata; sementara model bahasa besar dapat memprediksi probabilitas kalimat, paragraf, atau bahkan seluruh dokumen.
Ukuran dan kemampuan model bahasa telah berkembang pesat dalam beberapa tahun terakhir seiring dengan meningkatnya kapasitas memori komputer, ukuran dataset, dan daya pemrosesan, serta berkembangnya teknik yang lebih efektif untuk memodelkan urutan teks yang lebih panjang.
Hal yang membuat model ini “ besar ” bukan hanya karena ukuran data pelatihannya, melainkan juga karena jumlah “parameter” yang dimilikinya—yakni nilai-nilai numerik yang dipelajari model selama proses pelatihan dan berfungsi sebagai tombol-tombol penyetel dalam otaknya. Parameter inilah yang menentukan cara model mengolah input dan menghasilkan output, berdasarkan pola-pola yang telah dipelajarinya dari data sebelumnya. Parameter digunakan untuk memprediksi token (kata atau frase) berikutnya pada suatu urutan kata.
Sebagai perbandingan, model lama seperti BERT memiliki sekitar 110 juta parameter. Di sisi lain, model terbaru, seperti GPT-4 atau Gemini bisa memiliki ratusan miliar parameter. Kemampuannya jelas jauh berbeda!
Model-model ini telah dibor menggunakan komputer super berjam-jam, bahkan bisa berminggu-minggu. Semakin besar otak digital ini, semakin kompleks pula cara kerjanya.
Rahasia di Balik Kemampuan LLM: Transformers dan Self-Attention
Lompatan besar dalam AI terjadi saat diperkenalkannya Transformer , arsitektur yang menjadi fondasi bagi banyak model bahasa besar (Large Language Models atau LLM), yaitu ChatGPT, Gemini, Claude, dan lainnya.
Apa yang membuat Transformer begitu istimewa? Jawabannya: kemampuan memahami konteks secara menyeluruh dalam satu waktu .
Transformer tidak membaca satu demi satu kata secara berurutan. Ia membaca seluruh kalimat sekaligus dan bahkan bisa menganalisis hubungan antara kata-kata di seluruh bagian kalimat.
Bayangkan Anda sedang membaca novel dan tiba-tiba muncul kalimat, “Ia tersenyum, meski hati remuk.” Untuk memahami kalimat itu, Anda perlu konteks: siapa “ia”? Mengapa tersenyum? Apa yang terjadi sebelumnya?
Nah, Transformer memungkinkan model seperti LLM bisa memahami konteks panjang dan fokus pada bagian teks yang paling penting dari sebuah kalimat atau paragraf.
Misalnya dalam kalimat berikut.
Hewan itu tidak berada di seberang jalan karena terlalu lelah.
Perhatikan bahwa kalimat tersebut mengandung kata ganti it . Kata ganti sering kali ambigu. Kata ganti it selalu Merujuk pada kata benda yang baru saja disebutkan, tetapi dalam kalimat contoh ini, kata benda terbaru mana yang dirujuk oleh it : animal atau street ?
Transformer menggunakan mekanisme yang disebut self-attention untuk mencari tahu kata paling relevan. Self-attention merupakan cara canggih bagi model untuk “memperhatikan” kata-kata lain pada kalimat dalam memahami makna keseluruhan, mirip seperti seseorang yang mencoba memahami makna keseluruhan dari percakapan yang rumit.
Perhatian diri seperti memberi kesempatan setiap kata dalam kalimat untuk saling berbicara dan menanyakan hal berikut: "Apakah kamu penting buatku?"
Lalu, bukan hanya satu percakapan—pada Transformer , proses ini terjadi dalam banyak lapisan dan banyak arah . Beberapa lapisan fokus pada struktur kalimat, yang lain fokus terhadap makna, dan sisanya fokus pada hal-hal lebih dalam, seperti emosi atau nuansa dari kalimat tersebut.
Gambar berikut menunjukkan hasilnya—semakin biru garisnya, semakin penting kata tersebut bagi kata ganti " it ".
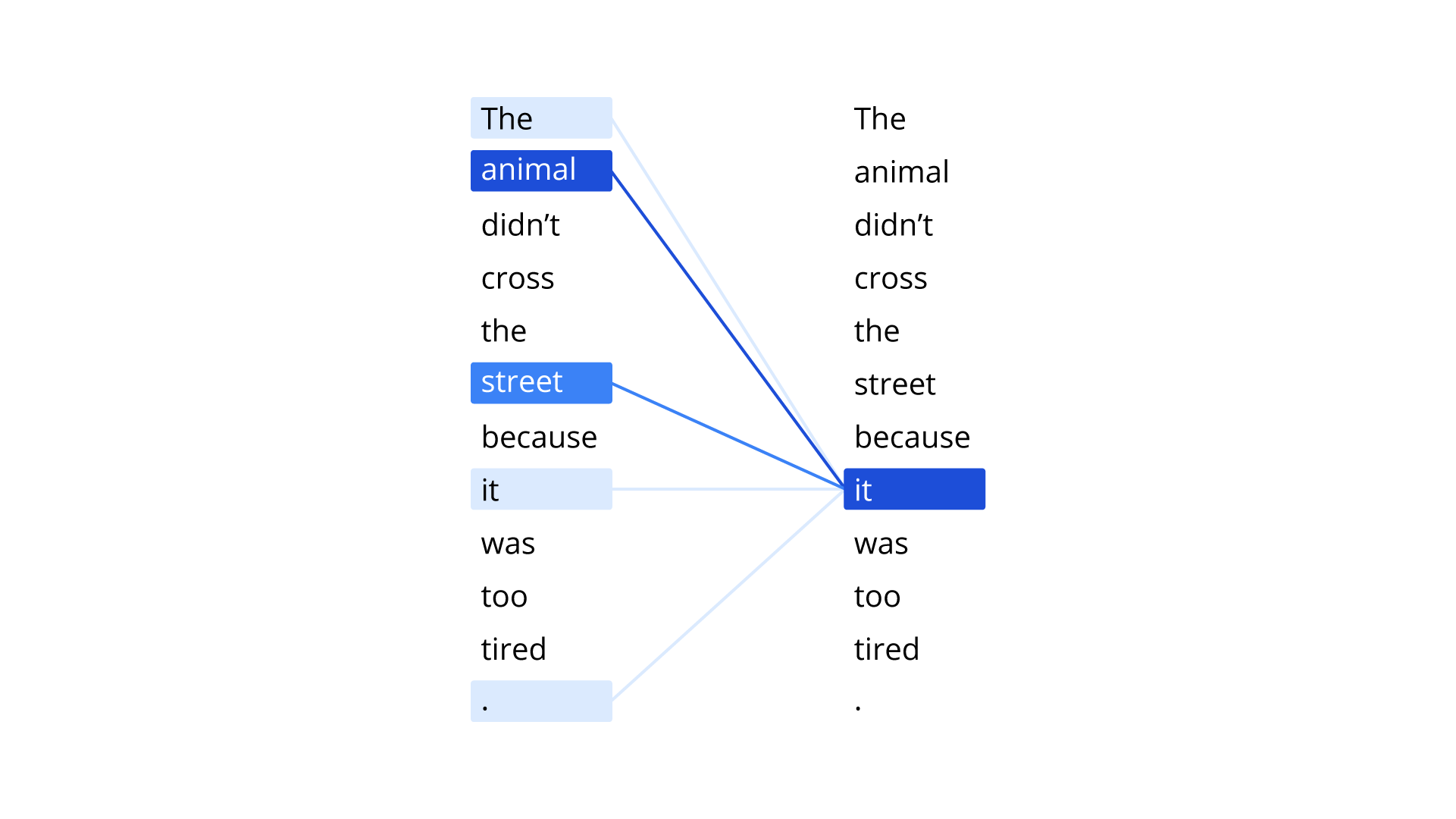
Dalam kasus ini, “ animal ” adalah referensi yang lebih masuk akal untuk “ it ” karena hewan bisa merasa lelah, sementara jalanan tidak.
Sebaliknya, hasilnya akan berubah misalkan kata terakhir dalam kalimat tersebut berubah sebagai berikut.
Hewan itu tidak melintasi jalan karena jalan itu terlalu lebar .
Dalam kalimat yang telah diubah tersebut, self-attention akan menilai " street " lebih relevan daripada " animal " bagi kata ganti " it " karena jalanan dapat bersifat lebar, sedangkan hewan tidak.
Dengan kemampuan ini, LLM tidak hanya memahami kalimat secara spesifik, tetapi juga memahami makna secara keseluruhan, seperti membaca pikiran penulis.
Semakin baik pemahaman konteks, semakin cerdas juga respon yang dihasilkan. Inilah alasan LLM tidak hanya digunakan untuk melengkapi kalimat, tetapi juga untuk menerjemahkan bahasa, merangkum artikel, menjawab pertanyaan, menulis kode, bahkan membuat lagu.
Di tangan yang tepat, LLM bisa menjadi asisten pribadi yang tak pernah lelah—membantu Anda menulis laporan, menyusun strategi, atau sekadar mencari inspirasi saat pikiran buntu.
Lompatan besar dalam AI terjadi saat diperkenalkannya Transformer , arsitektur yang menjadi fondasi bagi banyak model bahasa besar (Large Language Models atau LLM), yaitu ChatGPT, Gemini, Claude, dan lainnya.
Apa yang membuat Transformer begitu istimewa? Jawabannya: kemampuan memahami konteks secara menyeluruh dalam satu waktu .
Transformer tidak membaca satu demi satu kata secara berurutan. Ia membaca seluruh kalimat sekaligus dan bahkan bisa menganalisis hubungan antara kata-kata di seluruh bagian kalimat.
Bayangkan Anda sedang membaca novel dan tiba-tiba muncul kalimat, “Ia tersenyum, meski hati remuk.” Untuk memahami kalimat itu, Anda perlu konteks: siapa “ia”? Mengapa tersenyum? Apa yang terjadi sebelumnya?
Nah, Transformer memungkinkan model seperti LLM bisa memahami konteks panjang dan fokus pada bagian teks yang paling penting dari sebuah kalimat atau paragraf.
Misalnya dalam kalimat berikut.
Hewan itu tidak berada di seberang jalan karena terlalu lelah. |
Perhatikan bahwa kalimat tersebut mengandung kata ganti it . Kata ganti sering kali ambigu. Kata ganti it selalu Merujuk pada kata benda yang baru saja disebutkan, tetapi dalam kalimat contoh ini, kata benda terbaru mana yang dirujuk oleh it : animal atau street ?
Transformer menggunakan mekanisme yang disebut self-attention untuk mencari tahu kata paling relevan. Self-attention merupakan cara canggih bagi model untuk “memperhatikan” kata-kata lain pada kalimat dalam memahami makna keseluruhan, mirip seperti seseorang yang mencoba memahami makna keseluruhan dari percakapan yang rumit.
Perhatian diri seperti memberi kesempatan setiap kata dalam kalimat untuk saling berbicara dan menanyakan hal berikut: "Apakah kamu penting buatku?"
Lalu, bukan hanya satu percakapan—pada Transformer , proses ini terjadi dalam banyak lapisan dan banyak arah . Beberapa lapisan fokus pada struktur kalimat, yang lain fokus terhadap makna, dan sisanya fokus pada hal-hal lebih dalam, seperti emosi atau nuansa dari kalimat tersebut.
Gambar berikut menunjukkan hasilnya—semakin biru garisnya, semakin penting kata tersebut bagi kata ganti " it ".
Dalam kasus ini, “ animal ” adalah referensi yang lebih masuk akal untuk “ it ” karena hewan bisa merasa lelah, sementara jalanan tidak.
Sebaliknya, hasilnya akan berubah misalkan kata terakhir dalam kalimat tersebut berubah sebagai berikut.
Hewan itu tidak melintasi jalan karena jalan itu terlalu lebar . |
Dalam kalimat yang telah diubah tersebut, self-attention akan menilai " street " lebih relevan daripada " animal " bagi kata ganti " it " karena jalanan dapat bersifat lebar, sedangkan hewan tidak.
Dengan kemampuan ini, LLM tidak hanya memahami kalimat secara spesifik, tetapi juga memahami makna secara keseluruhan, seperti membaca pikiran penulis.
Semakin baik pemahaman konteks, semakin cerdas juga respon yang dihasilkan. Inilah alasan LLM tidak hanya digunakan untuk melengkapi kalimat, tetapi juga untuk menerjemahkan bahasa, merangkum artikel, menjawab pertanyaan, menulis kode, bahkan membuat lagu.
Di tangan yang tepat, LLM bisa menjadi asisten pribadi yang tak pernah lelah—membantu Anda menulis laporan, menyusun strategi, atau sekadar mencari inspirasi saat pikiran buntu.
Pertimbangan Penggunaan LLM
Sama seperti manusia, LLM juga punya kelebihan dan kekurangan. Terkait kelebihan, kami sudah bahas berkali-kali dalam materi sebelumnya. Jadi, sekarang mari kita bahas beberapa tantangan dan batasan LLM saat ini yang perlu dipertimbangkan.
Halusinasi Informasi
LLM bisa terdengar sangat meyakinkan saat menjawab pertanyaan, padahal jawaban yang diberikannya belum tentu benar, bahkan mungkin salah atau mengirim. Fenomena ini dikenal dengan istilah halusinasi , yakni kondisi ketika model menghasilkan informasi yang tidak akurat, tetapi disampaikan dengan cara logis dan janji; seolah-olah itu fakta.
Hal ini bisa terjadi karena LLM tidak benar-benar "mengerti" seperti manusia, tetapi hanya memprediksi kata atau frase yang paling mungkin muncul berdasarkan data pelatihan. Ia tidak memiliki pemahaman atau kesadaran seperti manusia. Ia tidak memiliki ingatan jangka panjang atau pengetahuan dunia nyata yang stabil. Setiap interaksi pada dasarnya bersifat prediktif dan terputus dari pengalaman sebelumnya, kecuali jika secara teknis diatur untuk menyimpan konteks.
Bias dalam Data Pelatihan
Karena LLM dibor menggunakan data yang diambil secara luas dari internet, mereka bisa saja menyerap informasi bias terkait sosial, politik, budaya, bahkan stereotip yang tertanam dalam data tersebut.
Ini berarti bahwa jika data dalam pelatihan model memuat ketimpangan, diskriminasi, ketidakadilan, atau informasi yang tidak proporsional, model pun berisiko menghasilkan atau memperkuat ketidakadilan dalam output-nya. Inilah alasan penting bagi pengguna untuk tetap kritis dan bijaksana, serta tidak mengambil hasil dari LLM sebagai kebenaran mutlak, kecuali dalam konteks pengambilan keputusan yang penting.
Semakin banyak orang mengandalkan LLM untuk menghasilkan teks atau membuat keputusan, semakin besar pula risiko ketika output tersebut tidak dikritisi dengan baik. Ini bisa menyebabkan penyebaran informasi yang salah atau membuat pengguna kehilangan daya kritis dalam menilai kebenaran informasi.
Infrastruktur dan Keberlanjutan
Di sisi lain, penggunaan LLM juga menghadirkan tantangan dari bidang infrastruktur dan kemiskinan. Melatih dan mengoperasikan model LLM sebesar ini memerlukan infrastruktur teknologi besar, termasuk konsumsi daya komputasi yang tinggi serta kebutuhan energi yang masif. Alhasil, memerlukan banyak biaya finansial serta dapat meninggalkan jejak karbon (carbon footprint ) yang perlu diperhitungkan.
Sebagai gambaran, sejumlah model besar memerlukan server khusus dan ratusan GPU selama berminggu-minggu hanya untuk satu kali pelatihan. Tentu saja hal ini berdampak pada konsumsi listrik besar-besaran serta jejak karbon yang signifikan.
Hal ini menjadi isu serius dalam upaya membangun teknologi yang tidak hanya canggih, tetapi juga etis dan berkelanjutan.
Selain energi, biaya pengembangan dan pemeliharaan LLM juga sangat tinggi. Hanya perusahaan besar dengan sumber daya melimpah yang mampu mengembangkan model seperti ini secara penuh, yang pada akhirnya juga dapat menciptakan ketimpangan akses teknologi.
Meski begitu, satu hal yang pasti: LLM telah hadir dalam kehidupan kita, dan mereka akan terus berkembang dari waktu ke waktu. Anda mungkin tidak menyadari hal tersebut. Namun, saat menggunakan fitur terjemahan otomatis, chatbot layanan pelanggan, atau bahkan mendengarkan musik, Anda sebenarnya sudah berinteraksi dengan LLM.
Model ini bukan hanya masa depan teknologi—mereka sudah hadir dalam keseharian kita. Kabarnya baik-baik saja? Anda tidak perlu menjadi ilmuwan untuk menggunakannya. Hal yang Anda perlukan hanyalah pemahaman, rasa ingin tahu, dan keberanian untuk mencoba.
Kini pertanyaannya adalah: apakah Anda siap memanfaatkan teknologi ini untuk mendongkrak produktivitas? Karena dengan pemahaman yang tepat, rasa ingin tahu, dan keberanian untuk bereksperimen, siapa pun—termasuk Anda—bisa menjadikan LLM sebagai mitra kerja yang luar biasa.
Rangkuman Mengenal Model Bahasa Besar (LLM)
Kenalan dengan Language Model
Dalam dunia AI, model bahasa adalah salah satu jenis model mesin pembelajaran yang bertugas untuk memprediksi kata berikutnya dalam sebuah kalimat. Ia bekerja seperti pemain menebak-tebakan kata yang sangat terlatih.
Jika seseorang berkata, “Kalau hujan turun di atap rumahku, aku biasanya…”, model ini akan mencoba menyelesaikannya dengan berbagai kemungkinan: tidur, masak mi, mendengarkan musik, dan seterusnya.
Model bahasa tidak hanya menebak secara sembarangan. Ia menimbang dan menghitung kata atau frase berikutnya dalam sebuah kalimat untuk menentukan pilihan yang paling masuk akal.
Model bahasa menghitung probabilitas berbagai kata berdasarkan pelatihan dari jutaan bahkan miliaran contoh kalimat yang pernah dipelajari sebelumnya.
Model akan memilih berdasarkan probabilitas tertinggi atau secara acak dari kandidat yang paling masuk akal. Semakin sering kombinasi kata tertentu muncul di dunia nyata (dalam data pelatihan), semakin tinggi kemungkinan model memilihnya.
LLM: Model Bahasa Versi Canggih
Seiring waktu, para ilmuwan dan insinyur komputer menyadari bahwa semakin besar model—semakin banyak data yang mereka pelajari serta semakin rumit struktur mereka—semakin pintar pula hasilnya.
Inilah yang disebut model bahasa besar atau LLM: versi super dari model bahasa yang dibor dengan jumlah data masif dan kapasitas pengiriman yang luar biasa . LLM adalah otak digital raksasa yang dapat berkomunikasi, menjawab pertanyaan, menulis cerita, merangkum artikel, bahkan menulis kode pemrograman.
Model bahasa awalnya hanya dapat memprediksi probabilitas dari satu kata; sementara model bahasa besar dapat memprediksi probabilitas kalimat, paragraf, atau bahkan seluruh dokumen.
Hal yang membuat model ini “ besar ” bukan hanya karena ukuran data pelatihannya, melainkan juga karena jumlah “parameter” yang dimilikinya—yakni nilai-nilai numerik yang dipelajari model selama proses pelatihan dan berfungsi sebagai tombol-tombol penyetel dalam otaknya. Parameter inilah yang menentukan cara model mengolah input dan menghasilkan output, berdasarkan pola-pola yang telah dipelajarinya dari data sebelumnya. Parameter digunakan untuk memprediksi token (kata atau frase) berikutnya pada suatu urutan kata.
Rahasia di Balik Kemampuan LLM: Transformers dan Self-Attention
Lompatan besar dalam AI terjadi saat diperkenalkannya Transformer , arsitektur yang menjadi fondasi bagi banyak model bahasa besar (Large Language Models atau LLM), yaitu ChatGPT, Gemini, Claude, dan lainnya.
Apa yang membuat Transformer begitu istimewa? Jawabannya: kemampuan memahami konteks secara menyeluruh dalam satu waktu .
Transformator tidak membaca satu demi satu kata secara berurutan. Ia membaca seluruh kalimat sekaligus dan bahkan bisa menganalisis hubungan antara kata-kata di seluruh bagian kalimat.
Transformator memungkinkan model seperti LLM dapat memahami konteks panjang dan fokus pada bagian teks yang paling penting dari sebuah kalimat atau paragraf.
Misalnya dalam kalimat berikut.
Hewan itu tidak berada di seberang jalan karena terlalu lelah. |
Perhatikan bahwa kalimat tersebut mengandung kata ganti it . Kata ganti sering kali ambigu. Kata ganti it selalu Merujuk pada kata benda yang baru saja disebutkan, tetapi dalam kalimat contoh ini, kata benda terbaru mana yang dirujuk oleh it : animal atau street ?
Transformer menggunakan mekanisme yang disebut self-attention untuk mencari tahu kata paling relevan. Perhatian pada diri sendiri merupakan cara canggih bagi model untuk “memperhatikan” kata-kata lain dalam kalimat untuk memahami makna keseluruhan, mirip seperti seseorang yang mencoba memahami makna keseluruhan dari percakapan yang rumit.
Perhatian diri seperti memberi kesempatan setiap kata dalam kalimat untuk saling berbicara dan menanyakan hal berikut. "Apakah kamu penting buatku?"
Lalu, bukan hanya satu percakapan—pada Transformer , proses ini terjadi dalam banyak lapisan dan banyak arah . Beberapa lapisan fokus pada struktur kalimat, yang lain fokus terhadap makna, dan sisanya fokus pada hal-hal lebih dalam, seperti emosi atau nuansa dari kalimat tersebut.
Dalam kasus ini, “ animal ” adalah referensi yang lebih masuk akal untuk “ it ” karena hewan bisa merasa lelah, sementara jalanan tidak.
Pertimbangan Penggunaan LLM
Sama seperti manusia, LLM juga punya kelebihan dan kekurangan.
Halusinasi Informasi
Hal ini bisa terjadi karena LLM tidak benar-benar "mengerti" seperti manusia, tetapi hanya memprediksi kata atau frase yang paling mungkin muncul berdasarkan data pelatihan. Ia tidak memiliki pemahaman atau kesadaran seperti manusia. Ia tidak memiliki ingatan jangka panjang atau pengetahuan dunia nyata yang stabil. Setiap interaksi pada dasarnya bersifat prediktif dan terputus dari pengalaman sebelumnya, kecuali jika secara teknis diatur untuk menyimpan konteks.
Bias dalam Data Pelatihan
Ini berarti bahwa jika data dalam pelatihan model memuat ketimpangan, diskriminasi, ketidakadilan, atau informasi yang tidak proporsional, model pun berisiko menghasilkan atau memperkuat ketidakadilan dalam output-nya. Inilah alasan penting bagi pengguna untuk tetap kritis dan bijaksana, serta tidak mengambil hasil dari LLM sebagai kebenaran mutlak, kecuali dalam konteks pengambilan keputusan yang penting.
Infrastruktur dan Keberlanjutan
Di sisi lain, penggunaan LLM juga menghadirkan tantangan dari bidang infrastruktur dan kemiskinan. Melatih dan mengoperasikan model LLM sebesar ini memerlukan infrastruktur teknologi besar, termasuk konsumsi daya komputasi yang tinggi serta kebutuhan energi yang masif. Alhasil, memerlukan banyak biaya finansial serta dapat meninggalkan jejak karbon (carbon footprint ) yang perlu diperhitungkan.
Bersambung ke:
Mengapa Etika Penting dalam Penggunaan AI?
- Get link
- X
- Other Apps



Comments
Post a Comment